







Recently, a student team from Communication University of China (CUC) achieved second place in the AI-Generated Video Quality Assessment Challenge at the 2025 NTIRE Workshop of the International Conference on Computer Vision and Pattern Recognition (CVPR), a top-tier conference in the field of computer vision. The team was guided by Professor Shi Ping from the Department of Radio and Television Engineering at CUC's School of Information and Communication Engineering, and consisted of Qi Zelu and Wang Shuqi, master's students in the Communication and Information Systems program, and Zhang Chaoyang, a doctoral student in the Information and Communication Engineering program.

The NTIRE Challenge, hosted by CVPR, is one of the most influential international competitions in the field of intelligent image restoration and enhancement. The 2025 CVPR NTIRE Workshop's XGC Quality Assessment Challenge featured multiple sub-tracks, with the AI-Generated Video Quality Assessment track focusing on multi-dimensional evaluation of AI-generated video quality, aiming to advance research in content understanding and quality modeling methods for AI-generated videos. The competition attracted over a hundred teams from universities, research institutions, and companies worldwide, including Beijing Institute of Technology, University of Science and Technology of China, and Shanghai Jiao Tong University.
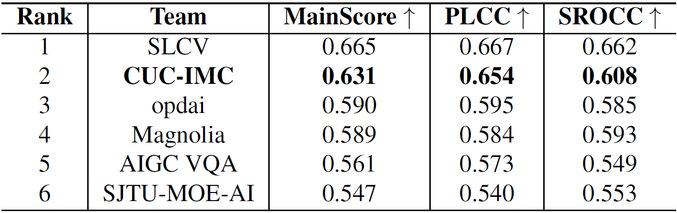
CVPR 2025 AI-Generated Video Quality Assessment Challenge Leaderboard (Top 6)
The task of the AI-Generated Video Quality Assessment track was to predict the perceptual quality score of AI-generated videos based on prompt-video pairs and their subjective quality evaluation labels (MOS scores). The competition results were determined by the consistency between the predicted results of the participating solutions and the MOS scores. The competition dataset included 34,029 videos generated by 14 mainstream video generation models, covering various distortion types, making the quality assessment task highly challenging.

Examples of Distortion Types in AI-Generated Videos from the Dataset
The CUC student team proposed a multi-branch encoder architecture to address common spatiotemporal distortions in AI-generated videos, decomposing visual quality into three dimensions: technical quality, motion quality, and semantic content, for comprehensive modeling. The team designed a multi-modal prompt engineering framework to align these three types of visual features into a language space, while introducing semantic anchors to assist large language models in establishing associative reasoning among the three features. During the training phase, the team used LoRA fine-tuning technology to task-specifically fine-tune the large language model, significantly improving the accuracy of quality prediction. The CUC team's solution was one of only two in the track that achieved over 60% consistency with MOS scores on the test set, demonstrating excellent modeling capabilities and practical performance. The related research results will be published in a paper at the CVPR 2025 Workshop.
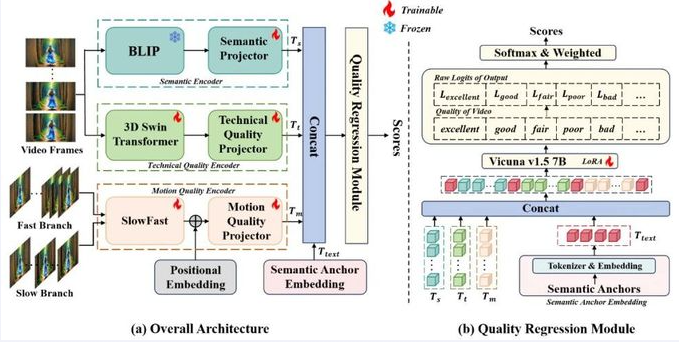
Overall Architecture Diagram of the Solution
The School of Information and Communication Engineering at CUC is closely aligned with the national artificial intelligence development strategy, continuously conducting original research in the field of video quality assessment technology, exploring effective evaluation methods for video understanding and generation, and contributing wisdom and solutions to the standardized development of AI generation technology.
*Article translated by a large language model.
Editor: Li Jichu




